layout: post
title: 大数据分析引擎Apache Flink 初见 Apache顶级项目[学习中]
categories: Java, Scala,Hadoop,Flink
description: Java, Scala,Hadoop,Flink
keywords: Java, Scala,Hadoop,Flink
Apache Flink是一个高效、分布式、基于Java实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API
从Flink官网得知,其具有如下主要特征:
1. 快速
Flink利用基于内存的数据流并将迭代处理算法深度集成到了系统的运行时中,这就使得系统能够以极快的速度来处理数据密集型和迭代任务。
2. 可靠性和扩展性
当服务器内存被耗尽时,Flink也能够很好的运行,这是因为Flink包含自己的内存管理组件、序列化框架和类型推理引擎。
3. 表现力
利用Java或者Scala语言能够编写出漂亮、类型安全和可为核心的代码,并能够在集群上运行所写程序。开发者可以在无需额外处理就使用Java和Scala数据类型
4. 易用性
在无需进行任何配置的情况下,Flink内置的优化器就能够以最高效的方式在各种环境中执行程序。此外,Flink只需要三个命令就可以运行在Hadoop的新MapReduce框架Yarn上,
5. 完全兼容Hadoop
Flink支持所有的Hadoop所有的输入/输出格式和数据类型,这就使得开发者无需做任何修改就能够利用Flink运行历史遗留的MapReduce操作
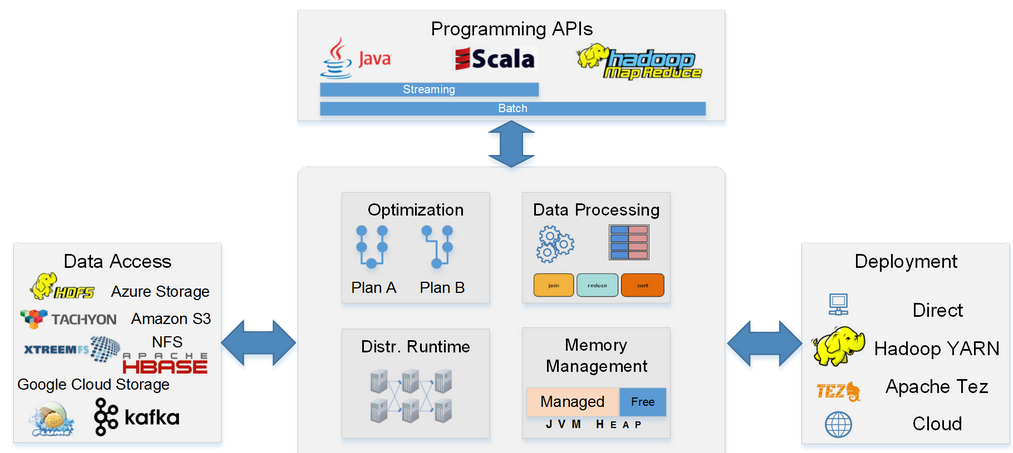
Flink主要包括基于Java和Scala的用于批量和基于流数据分析的API、优化器和具有自定义内存管理功能的分布式运行时等,其主要架构如下:
6. DEMO
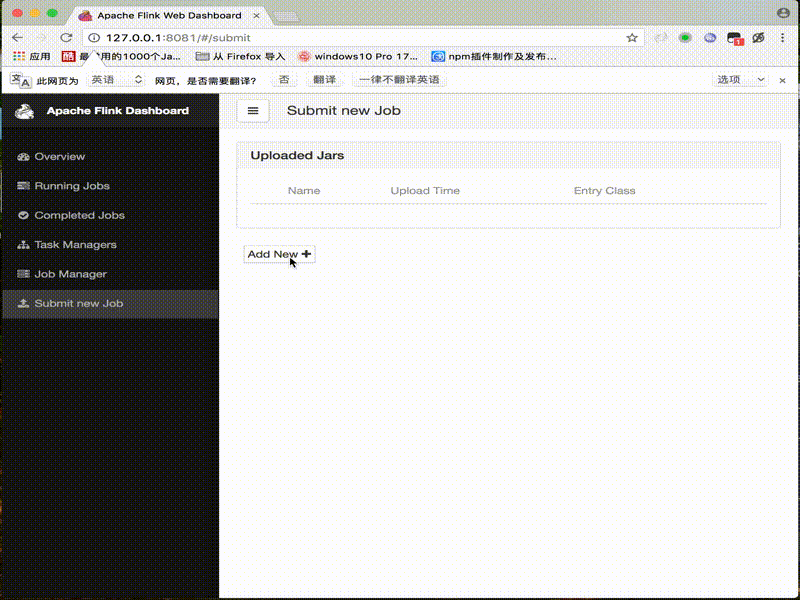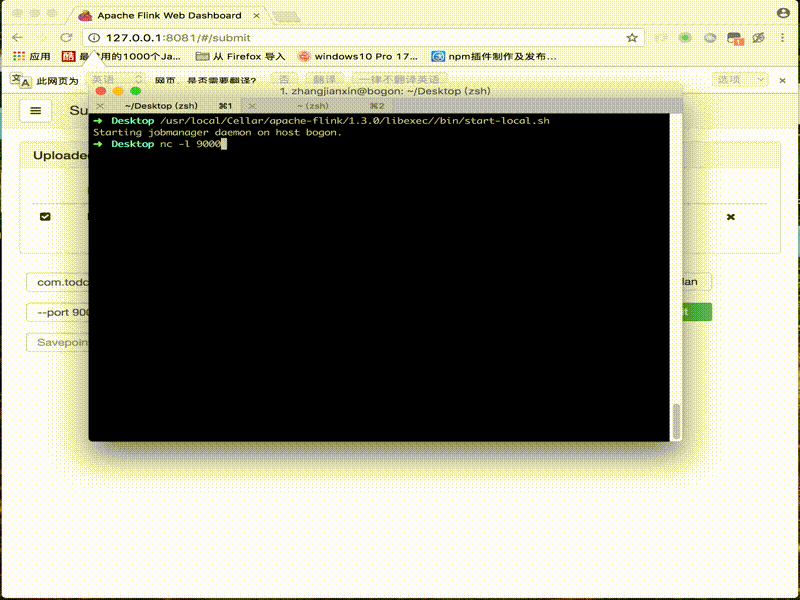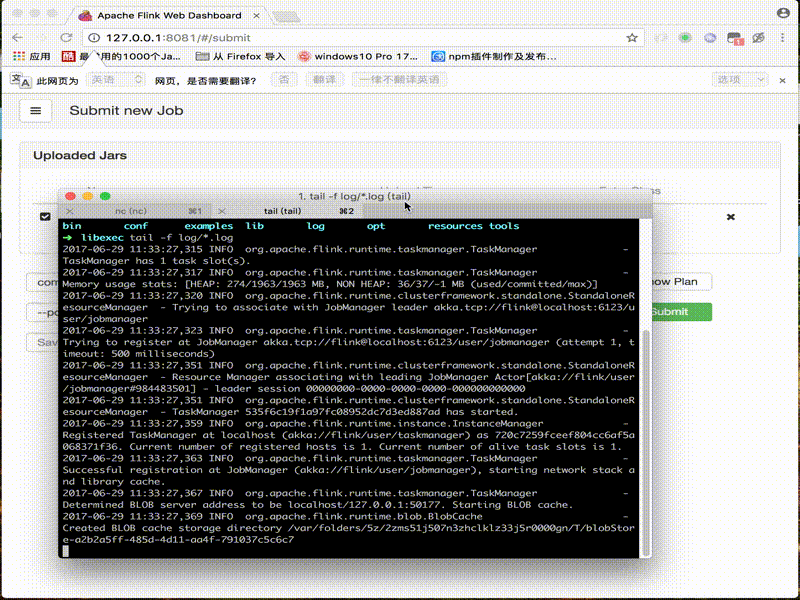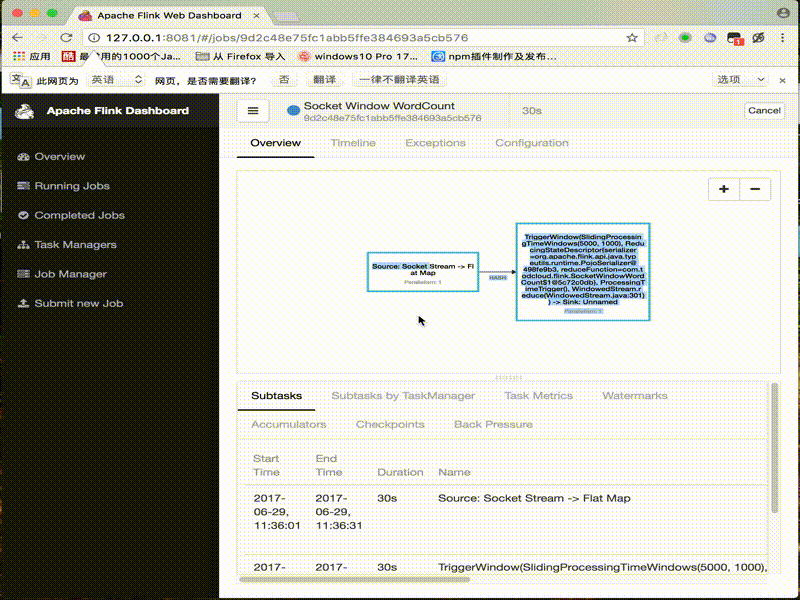
架构图

logo